算法分析笔记:贪心算法
贪心算法(Greedy Algorithm) 1.算法基本思想 最优子结构的情况下可用动态规划法,但有时也会有更加简单有效的方法。贪心算法就是在解决子问题时,总是做出当前问题的最好判断。可以说其解决思路是短视和局部的,它并不考虑整体的最优解,只专注于局部问题的解。
上面的描述来看,贪心算法更加直接和高效,但其局限性也很大:很多问题的最优解并不是直接解决其子问题最优解就能得出来的。虽然贪心算法显然不能解决所有问题,但我们依旧可以用它来获得局部的最优解。
1.1 贪心选择性质 上面提到,贪心算法仅在当前问题中做最优解。其选择可以依赖于其曾今的解,但是绝对不会依赖于之后所做的选择。所以该算法通常使用自顶向下的解决顺序。
1.2
贪心算法与动态规划算法的差别 两种算法皆具有最优子结构性质。在笔者的上一篇笔记《算法分析笔记:动态规划》 中有提到0-1背包问题 。与这个问题类似的一个问题为背包问题 。
背包问题 与0-1背包问题类似的,给定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void knapsack (int a, float M, float v[], float w[], float x[]) Sort (n,v,w);int i;for (i = 1 ; i <= n; i++)0 ;float c = M;for (i = 1 ;i <= n; i++)if (w[i] > c)break ;1 ;if (i <= n)
上述算法计算时间上界为
2.算法应用问题 2.1 单源最短路径(Single
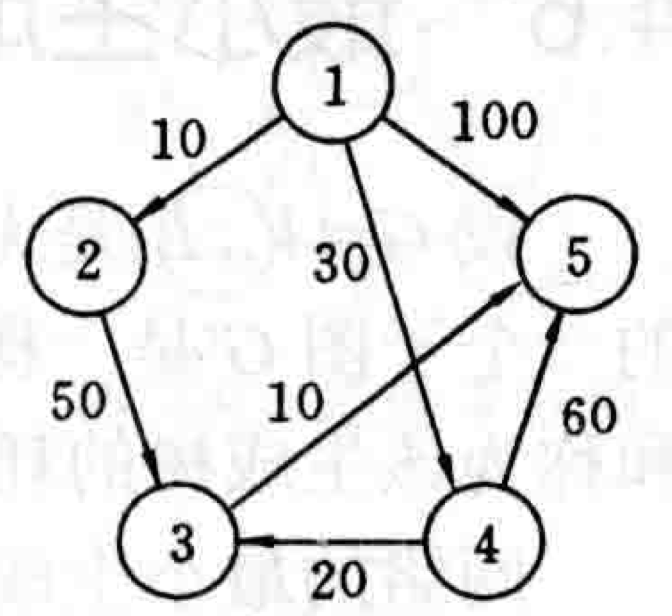
Source Shortest Path) 2.1.1 问题描述 给定一个带权有向图
2.1.2 Dijkstra算法 Dijkstra算法是贪心算法设计策略的又一个典型例子。在
我们这样描述Dijkstra算法:输入带权有向图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 template <class Type >void Dijkstra (int n, int v, Type dist[], int prev[], Type **c) bool s[maxint]; for (int i = 1 ; i <= n; i++)false ;if (dist[i] == maxint)0 ;else 0 ;true ;for (int i = 1 ; i < n; i++)int u = v;for (int j = 1 ; j <= n; j++)if ((!s[j]) && (dist[j] < temp))true ;for (int j = 1 ; j <= n; j++)if ((!s[j]) && (c[u][j] < maxint))if (newdist < dist[j])
以上算法总体需要
对于上面2.2.1问题描述中给出的一个有向图,我们计算从源顶点1到其它顶点的最短路径,推演其迭代过程,使用表格记录:
初始
{1}
--
10
maxint
30
100
1
{1,2}
2
10
60
30
100
2
{1,2,4}
4
10
50
30
90
3
{1,2,4,3}
3
10
50
30
60
4
{1,2,4,3,5}
5
10
50
30
60
上述算法具体的过程解析可以参考这篇推文:《图文详解
Dijkstra 最短路径算法》
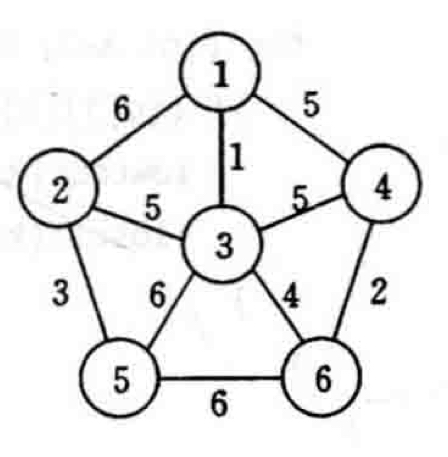
2.2 最小生成树(Minimum Spanning
Tree) 2.2.1 问题描述 设
解决该问题之前,我们需要了解其的性质。设
2.2.2 Prim算法 对于上面所说的
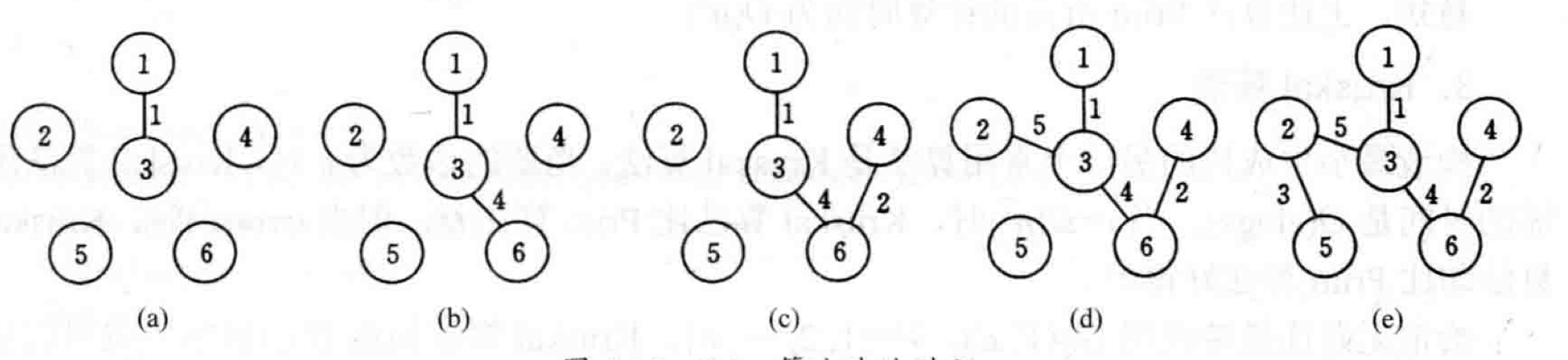
下图为Prim算法的图片过程:
简单来说,该算法将原图打散,从出发点开始,统计所有连接着已经过点和未经过点的边,并找到最短的一条,将其连接的原未经过点加入到已经过点中并循环改过程。下面是基本代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 template <class Type >void Prim (int n, Type** c) int closest[maxint];bool s[maxint];1 ] = true ;for (int i = 2 ; i <= n; i++)1 ][i];1 ;false ;for (int i = 1 ; i < n; i++)int j = 1 ;for (int k = 2 ; k <= n; k++)if ((lowcost[k] < min) && (!s[k]))"(" << closest[j] << "," << j << ")" << endl;
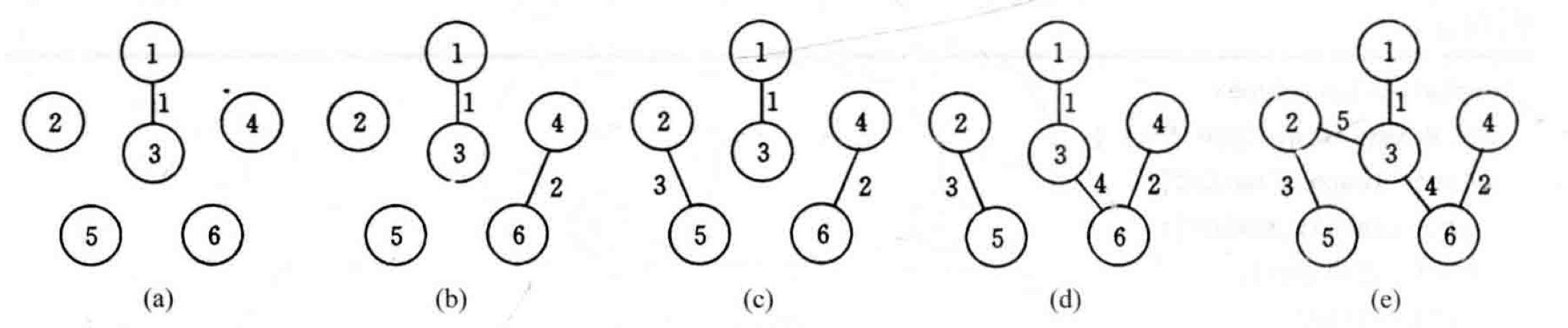
2.2.3 Kruskal算法 Kruskal算法是解决最小生成树问题的另一种常用算法。如果说Prim算法是以相邻顶点为出发点,通过连接最短边的方式找到下一个点,那么Kruskal算法则是先找最短边,使用以边为出发点找到对应点来构建最小生成树。
算法的基本思想是:先将图中每个顶点看成独立的分支,将所有边按从大到小排列,依次观察该边是否连接了两个独立的分支。如果是,则将该边以及对应顶点加入到树中,否则直接查看下一条。完成所有边的验证后,得到的就是最小生成树。
以下为算法的基本代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 template <class Type >class EdgeNode operator << (ostream&,EdgeNode<Type>);friend bool Kruskal (int , int , EdgeNode<Type>*, EdgeNode<Type>* ) friend void main (void ) public :operator Type () const {return weight;private :int u, v;template <class Type >bool Kruskal (int n, int e, EdgeNode<Type> E[], EdgeNode<Type> t[]) H (1 ); Initialize (E, e, e);UnionFind UF (n) ; int k = 0 ;while (e && k < n-1 )int > x;DeleteMin (x);int a = U.Find (x.u);int b = U.Find (x.v);if (a != b)Union (a, b);Deactivate (x);return (k == n-1 );
对于一个有
由此可以看出,当