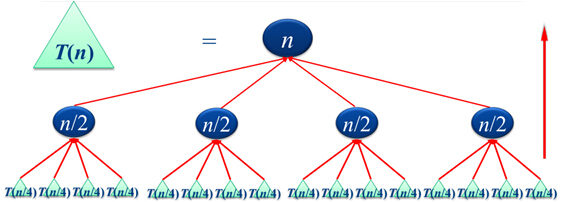
template <classType> voidMergeSort(Type *a, int n) { Type *b = new Type[n]; int seg = 1; while (seg < n) { MergePass(a, b, seg, n); //合并至数组b seg += seg; MergePass(b, a, seg, n); //合并至数组a seg += seg; } }
template <classType> voidQuickSort(Type *a, int p, int r)//算法主函数 { if (p < r) { int q = Partition(a, p, r); //获取基准元素的位置 QuickSort(a, p, q - 1); //对左边元素进行排序 QuickSort(a, q + 1, r); //对右边元素进行排序 } }
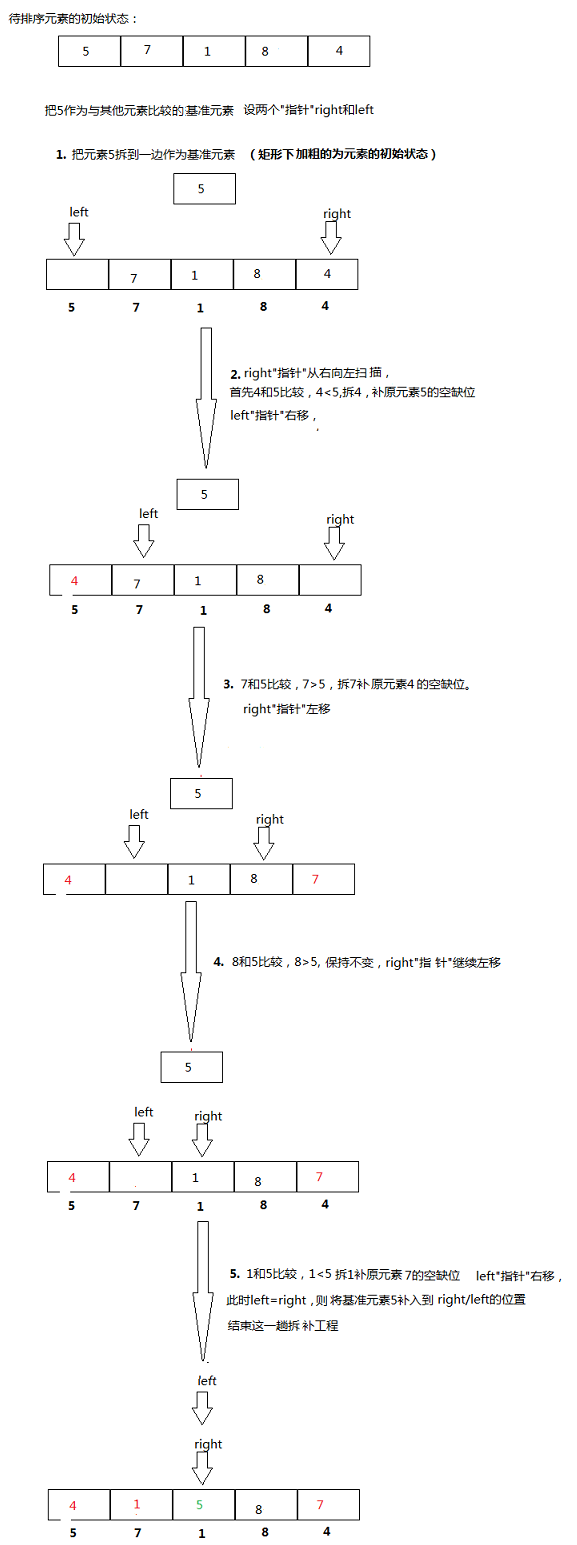
template <classType> intPartiton(Type *a, int p, int r) { int i = p, j = r+1; Type x = a[p]; //基准元素 while (true) { while (a[++i] < x && i < r); //从左向右找到第一个大于x的元素 while (a[--j] > x); //从右向左找到第一个小于x的元素 if (i >= j) break; //如果两个指针相遇,则退出循环 swap(a[i], a[j]); //交换两个元素 } a[p] = a[j]; //将基准元素放到正确的位置 a[j] = x; return j; //返回基准元素的位置 }
template <classType> intRandomizedPartition(Type *a, int p, int r) { int i = p + rand() % (r - p + 1); //随机选择基准元素 swap(a[i], a[p]); returnPartition(a, p, r); }
基于上述代码,我们可以得到线性时间选择的基本代码:
1 2 3 4 5 6 7 8 9 10 11 12
template <classType> intRandomizedSelect(Type *a, int p, int r, int k) { if (p == r) return a[p]; int i = RandomizedPartition(a, p, r); int j = i - p + 1; if (k <= j) returnRandomizedSelect(a, p, i, k); else returnRandomizedSelect(a, i + 1, r, k - j); }
template <classType> Type Select(Type *a,int p, int r, int k) { if(r-p<75) { 对a[p:r]进行排序; return a[p+k-1]; } for(int i = 0; i <= (r-p-4)/5; i++) { 将a[p+5*i]至a[p+5*i+4]的第三小元素与a[p+i]交换; Type x = Select(a,p,p+(r-p-4)/5,(r-p-4)/10); //找中位数的中位数 int i = Partition(a,p,r,x), j = i-p+1; if(k<=j) returnSelect(a,p,i,k); else returnSelect(a,i+1,r,k-j); } }